
Table of Contents
ToggleTF IDF full form is term frequency-inverse document frequency. It is a statistical measure used to find the importance of a word in a document relative to a collection.
In Tf-idf we have two components i.e. Term frequency and Inverse document frequency.
Term frequency (TF) measures how frequency a word appears in the document. More the frequency of the word in the document, more important a word for that specific document. The formula of term frequency is
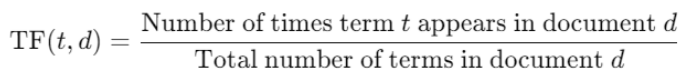
Inverse Document Frequency (IDF) measures how important a word is across the entire corpus.
The words which appear in many documents are less informative than terms that appear in fewer documents. The formula of inverse document frequency is

The TF-IDF score is calculated as product of TF and IDF.
Why we use TF-IDF ?
TF-IDF transforms text into numerical representation which makes it suitable for machine learning model like text classification and clustering.
It also helps us measure the importance of words in a document relative to entire corpus. It provides importance by giving words weight. Greater the weight more important the word. TF-IDF difference from word embedding like Word2vec or GloVe as it provides important terms compared to semantic relation gives in Word2vec or GloVe.
In this blog, we will go through various Python TF IDF Code. We will see how TF IDF is implemented in Python using Sklearn with example. The use of TF IDF in k means and classification algorithm would also be explored.
TF-IDF Example Using sklearn in Python
The code shows how to compute TF idf score using sklearn library in Python. We will get TF IDF scores of words in a set of documents.
from sklearn.feature_extraction.text import TfidfVectorizer
A list of sample documents on which we will be performing TF IDF.
documents = [
"the cat and the hat are friends",
"the fox jumps over the lazy dog"
]
Creating a TF-IDF Vectorizer
vectorizer = TfidfVectorizer()
Fit and transform the documents
tfidf_matrix = vectorizer.fit_transform(documents)
Getting the words corresponding to features
feature_names = vectorizer.get_feature_names_out()
Converting the matrix to an array and printing it
tfidf_array = tfidf_matrix.toarray()
for i in range(len(documents)):
print(f"Document {i + 1} TF-IDF:")
for j in range(len(feature_names)):
print(f"{feature_names[j]}: {tfidf_array[i][j]}")
print("\n")
Output
Document 1 TF-IDF: and: 0.3772919866524395 are: 0.3772919866524395 cat: 0.3772919866524395 dog: 0.0 fox: 0.0 friends: 0.3772919866524395 hat: 0.3772919866524395 jumps: 0.0 lazy: 0.0 over: 0.0 the: 0.5368927118515179 Document 2 TF-IDF: and: 0.0 are: 0.0 cat: 0.0 dog: 0.3772919866524395 fox: 0.3772919866524395 friends: 0.0 hat: 0.0 jumps: 0.3772919866524395 lazy: 0.3772919866524395 over: 0.3772919866524395 the: 0.5368927118515179
Extracting TF IDF top words using Python
import numpy as npThe function get_top_n_words() get top N words. The function requires input tf idf matrix, list of unique words in corpus i.e. feature_names and number of top keywords you want i.e. n.
def get_top_n_words(tfidf_matrix, feature_names, n=5):
# Get the index of the highest scores
sorted_indices = np.argsort(tfidf_matrix.toarray(), axis=1)[:, -n:]
top_words = {}
for doc_index in range(tfidf_matrix.shape[0]):
top_words[doc_index] = [(feature_names[i], tfidf_matrix[doc_index, i]) for i in sorted_indices[doc_index]]
return top_words
Looping over top words.
top_n_words = get_top_n_words(tfidf_matrix, feature_names, n=2)
for doc_index, words in top_n_words.items():
print(f"Top words in Document {doc_index + 1}: {words}")
Output
Top words in Document 1: [('hat', 0.3772919866524395), ('the', 0.5368927118515179)]
Top words in Document 2: [('over', 0.3772919866524395), ('the', 0.5368927118515179)]
K-means Clustering with TF-IDF in Python
The below implements TF IDF in Kmeans algorithm using Python.We will try to find 2 cluster in the Newsgropus dataset just as a experiment.
The Newsgroups dataset consists of approximately 20,000 documents organized into 20 different categories. It covering a wide range of topics like technology, sports, and politics.
Importing libraries
import numpy as np from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.cluster import KMeans
Loading the dataset.
newsgroups = fetch_20newsgroups(subset='all', categories=['rec.sport.baseball', 'sci.space'], remove=('headers', 'footers', 'quotes'))
Performing Vectorization
vectorizer = TfidfVectorizer(stop_words='english') tfidf_matrix = vectorizer.fit_transform(newsgroups.data)
Implementing Kmeans Clustering with 2 clusters
num_clusters = 2 kmeans = KMeans(n_clusters=num_clusters, random_state=42) kmeans.fit(tfidf_matrix)
Printing Cluster labels
print("Cluster labels for first 5 document:")
for i, label in enumerate(kmeans.labels_):
print(f"Document {i + 1}: Cluster {label}")
if i==5:
break
Output
Cluster labels for each document: Document 1: Cluster 1 Document 2: Cluster 1 Document 3: Cluster 1 Document 4: Cluster 1 Document 5: Cluster 1 Document 6: Cluster 1
Document Classification using TF-IDF
import numpy as np from sklearn.datasets import fetch_20newsgroups from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report, accuracy_scoreLoading the 20 Newsgroups dataset
newsgroups = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
Creating the TF-IDF vectorizer
vectorizer = TfidfVectorizer(stop_words='english')Fitting and transforming the documents into a TF-IDF matrix
X = vectorizer.fit_transform(newsgroups.data) y = newsgroups.targetSplitting the dataset into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Initializing the classifier model (Multinomial Naive Bayes)
classifier = MultinomialNB()Fit the classifier on the training data
classifier.fit(X_train, y_train)Making predictions on the test data
y_pred = classifier.predict(X_test)Evaluating the model
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred, target_names=newsgroups.target_names))
Output
Accuracy: 0.7196286472148541
Classification Report:
precision recall f1-score support
alt.atheism 0.75 0.27 0.40 151
comp.graphics 0.70 0.68 0.69 202
comp.os.ms-windows.misc 0.67 0.66 0.66 195
comp.sys.ibm.pc.hardware 0.55 0.78 0.64 183
comp.sys.mac.hardware 0.87 0.67 0.75 205
comp.windows.x 0.90 0.81 0.85 215
misc.forsale 0.79 0.70 0.74 193
rec.autos 0.84 0.76 0.79 196
rec.motorcycles 0.49 0.77 0.60 168
rec.sport.baseball 0.92 0.83 0.88 211
rec.sport.hockey 0.88 0.92 0.90 198
sci.crypt 0.70 0.85 0.77 201
sci.electronics 0.85 0.62 0.72 202
sci.med 0.91 0.86 0.88 194
sci.space 0.80 0.83 0.81 189
soc.religion.christian 0.42 0.94 0.58 202
talk.politics.guns 0.70 0.79 0.74 188
talk.politics.mideast 0.78 0.83 0.80 182
talk.politics.misc 0.92 0.43 0.58 159
talk.religion.misc 0.80 0.03 0.06 136
accuracy 0.72 3770
macro avg 0.76 0.70 0.69 3770
weighted avg 0.76 0.72 0.71 3770
Implementing tf-idf from scratch in Python
We will see a step by step implementation of TF IDF from scratch in Python.
Step 1: Install Required Libraries
pip install nltk numpy
Step 2: Import Libraries and Prepare Data
import nltk
import numpy as np
import math
from collections import Counter
Some sample records used as out corpus
documents = [
"the cat in the hat",
"the quick brown fox",
"the cat and the hat are friends",
"the fox jumps over the lazy dog"
]
Tokenizing the documents using nltk
nltk.download('punkt')
tokenized_docs = [nltk.word_tokenize(doc.lower()) for doc in documents]
Step 3: Computing Term Frequency (TF) based on formula
from collections import Counter
def compute_tf(tokenized_docs):
"""
Compute Term Frequency (TF) for each document in a list of tokenized documents.
Parameters:
tokenized_docs (list of list of str): A list where each element is a list of tokens (words) for a document.
Returns:
list of dict: A list of dictionaries, each containing the term frequencies for a corresponding document.
"""
tf_list = [] # Initialize a list to hold the TF scores for each document
# Iterate through each document's tokens
for tokens in tokenized_docs:
# Count the frequency of each token in the document
count = Counter(tokens)
# Calculate the term frequency for each word
tf = {word: freq / len(tokens) for word, freq in count.items()}
# Append the TF dictionary to the list
tf_list.append(tf)
return tf_list # Return the list of TF scores for all documents
# Example usage of the compute_tf function
tf_scores = compute_tf(tokenized_docs) # Compute the TF scores for the tokenized documents
# Print the TF scores for each document
print("TF Scores:")
for i, tf in enumerate(tf_scores):
print(f"Document {i + 1}: {tf}") # Display the TF scores for each document
Output
TF Scores:
Document 1: {'the': 0.4, 'cat': 0.2, 'in': 0.2, 'hat': 0.2}
Document 2: {'the': 0.25, 'quick': 0.25, 'brown': 0.25, 'fox': 0.25}
Document 3: {'the': 0.2857142857142857, 'cat': 0.14285714285714285, 'and': 0.14285714285714285, 'hat': 0.14285714285714285, 'are': 0.14285714285714285, 'friends': 0.14285714285714285}
Document 4: {'the': 0.2857142857142857, 'fox': 0.14285714285714285, 'jumps': 0.14285714285714285, 'over': 0.14285714285714285, 'lazy': 0.14285714285714285, 'dog': 0.14285714285714285}
Step 4: Computing Inverse Document Frequency based on formula
import math
def compute_idf(tokenized_docs):
"""
The function computes Inverse Document Frequency (IDF) for each unique word in a list of tokenized documents.
Input parameters of function:
tokenized_docs (list of list of str): A list where each element is a list of tokens (words) for a document.
Returns:
dict: A dictionary where keys are words and values are their corresponding IDF scores.
"""
n = len(tokenized_docs) # Total number of documents
idf = {} # Initialize a dictionary to hold IDF scores
# Create a set of all unique words across all documents
all_words = set(word for tokens in tokenized_docs for word in tokens)
# Calculate IDF for each unique word
for word in all_words:
# Count how many documents contain the word (document frequency)
df = sum(1 for tokens in tokenized_docs if word in tokens)
# Compute the IDF score using the formula: log(n / (1 + df))
idf[word] = math.log(n / (1 + df)) # Add 1 to avoid division by zero
return idf # Return the dictionary of IDF scores
# Example usage of the compute_idf function
idf_scores = compute_idf(tokenized_docs) # Compute the IDF scores for the tokenized documents
# Print the IDF scores for each word
print("\nIDF Scores:")
print(idf_scores) # Display the IDF scores
Output
IDF Scores:
{'in': 0.6931471805599453, 'jumps': 0.6931471805599453, 'brown': 0.6931471805599453, 'over': 0.6931471805599453, 'are': 0.6931471805599453, 'cat': 0.28768207245178085,
'lazy': 0.6931471805599453, 'the': -0.2231435513142097, 'fox': 0.28768207245178085, 'quick': 0.6931471805599453, 'friends': 0.6931471805599453, 'and': 0.6931471805599453, 'hat': 0.28768207245178085, 'dog': 0.6931471805599453}
Step 5: Compute TF-IDF
We can combine the TF and IDF scores to compute TF-IDF:
def compute_tf_idf(tf_scores, idf_scores):
"""
The function Computes TF-IDF scores for each document using the term frequency (TF) scores
and the inverse document frequency (IDF) scores.
Input Parameters of the function:
tf_scores (list of dict): A list where each dictionary contains the TF scores for a document.
idf_scores (dict): A dictionary where keys are words and values are their corresponding IDF scores.
Returns:
list of dict: A list of dictionaries, each containing the TF-IDF scores for a corresponding document.
"""
tf_idf_list = [] # Initialize a list to hold the TF-IDF scores for each document
# Iterate through each document's TF scores
for tf in tf_scores:
# Compute TF-IDF for each word in the document
tf_idf = {word: tf_val * idf_scores[word] for word, tf_val in tf.items()}
# Append the TF-IDF dictionary to the list
tf_idf_list.append(tf_idf)
return tf_idf_list # Return the list of TF-IDF scores for all documents
# Example usage of the compute_tf_idf function
tf_idf_scores = compute_tf_idf(tf_scores, idf_scores) # Compute the TF-IDF scores using the TF and IDF scores
# Print the TF-IDF scores for each document
print("\nTF-IDF Scores:")
for i, tfidf in enumerate(tf_idf_scores):
print(f"Document {i + 1}: {tfidf}") # Display the TF-IDF scores for each document
Output
TF-IDF Scores:
Document 1: {'the': -0.08925742052568389, 'cat': 0.05753641449035617, 'in': 0.13862943611198905, 'hat': 0.05753641449035617}
Document 2: {'the': -0.05578588782855243, 'quick': 0.17328679513998632, 'brown': 0.17328679513998632, 'fox': 0.07192051811294521}
Document 3: {'the': -0.06375530037548849, 'cat': 0.04109743892168297, 'and': 0.09902102579427789, 'hat': 0.04109743892168297, 'are': 0.09902102579427789, 'friends': 0.09902102579427789}
Document 4: {'the': -0.06375530037548849, 'fox': 0.04109743892168297, 'jumps': 0.09902102579427789, 'over': 0.09902102579427789, 'lazy': 0.09902102579427789, 'dog': 0.09902102579427789}
Comparing TF-IDF with Word Embeddings like Word2Vec, GloVe etc
TF IDF is not word embedding technique it a statistical measure for finding important keywords in the document. Word2Vec and GloVe are Word embeddings techniques which capture semantic meanings.
You can also read about what does bottom layer of decision tree teel ?