Table of Contents
ToggleWhy is normalization necessary?
You can consider normalization as a way of scaling and shifting the input data in a particular range. Some common normalization techniques are min-max normalization and z-score (standardization) normalization.
Min max normalization scales data between 0 to 1 whereas standardization scales data to have mean of 0 and stand deviation of 1.
The real world data contains input features of different scales. Consider the dataset of employee‘s salary, where we have different input features like age, experience, designation, salary etc. If you see the salary and age value range, the salary falls between $700 to $1000 and the age is between 18 years to 60 years. When we train a neural network with an employee’s salary dataset, the amount of time taken by the gradient descent algorithm to move the center is high.
When the values are high and propagated through the layers of the neural network which causes higher error gradient making the training process unstable and causes the problem of exploding gradient problem.
It also solves the problem of internal covariate shift. It refers to a process where the data keeps on changing which goes in the neural network as the neural network learns.
You can also learn how to export pandas dataframe to excel without index.
Layer normalization vs Batch normalization
Point 1 : Batch normalization normalizes each feature within a batch of samples, whereas Layer normalization normalizes all features within each individual sample.
The sample and feature referred to in the above context are row and column respectively. This makes the understanding better.
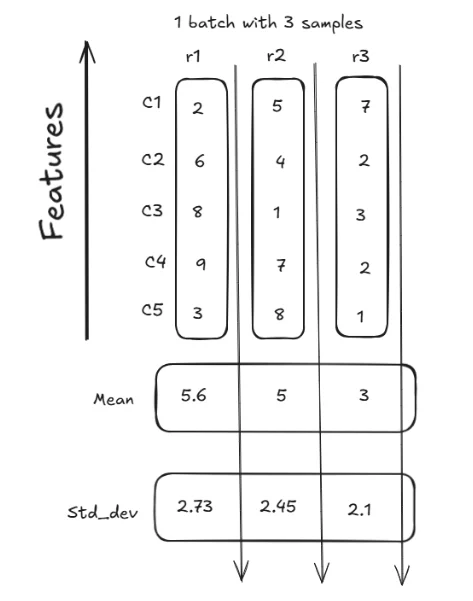
Let me explain that with a diagram. Consider we have a dataset for training. The training dataset is divided into batches. Consider each batch has three rows and 5 columns for demonstration purposes.
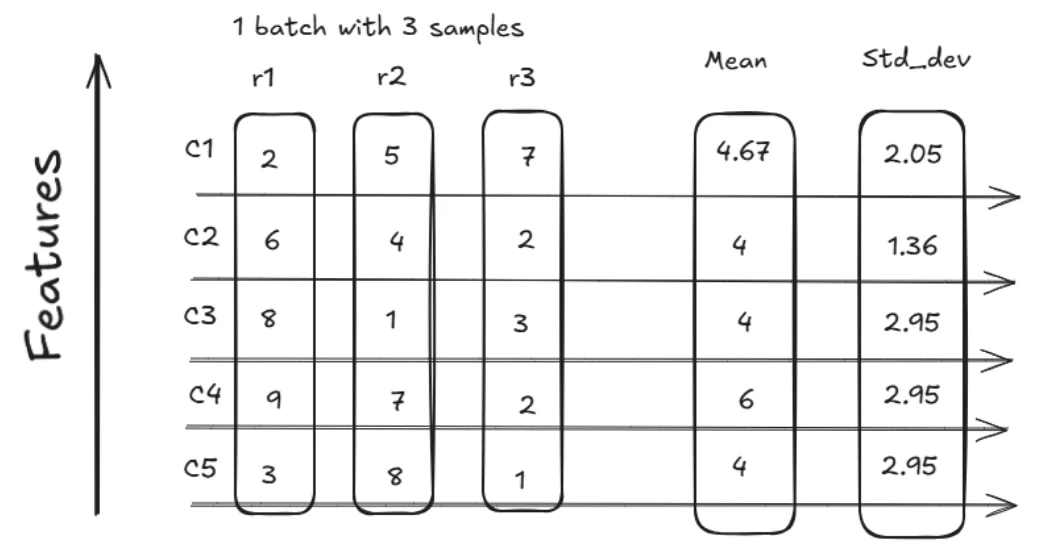
In the above diagram Features are the columns (c1, c2, c3, c4 and c5) on Y axis and rows are on x axis (r1, r2 and r3).
In batch normalization the mean and standard deviation are calculated for each column across rows. In our case the mean and standard deviation is calculated for column c1 which would be Mc and Sc.
Now, let calculate the mean of first column which has values 2,5 and 7.
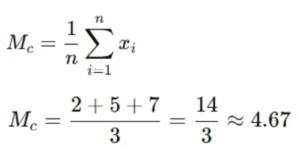
Mean is 4.67 .
Similarly, let’s get the standard deviation
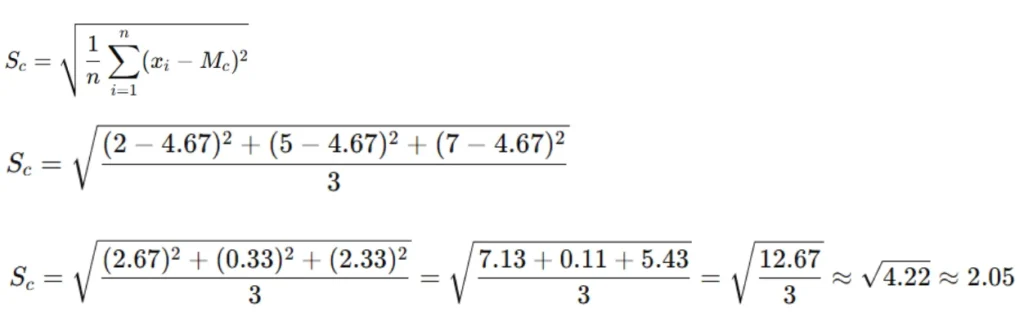
So, the standard deviation is approximately 2.05.
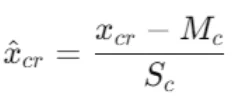
Where cap xcr is the value normalized and xcr is the value from the column
Calculating the normalized values
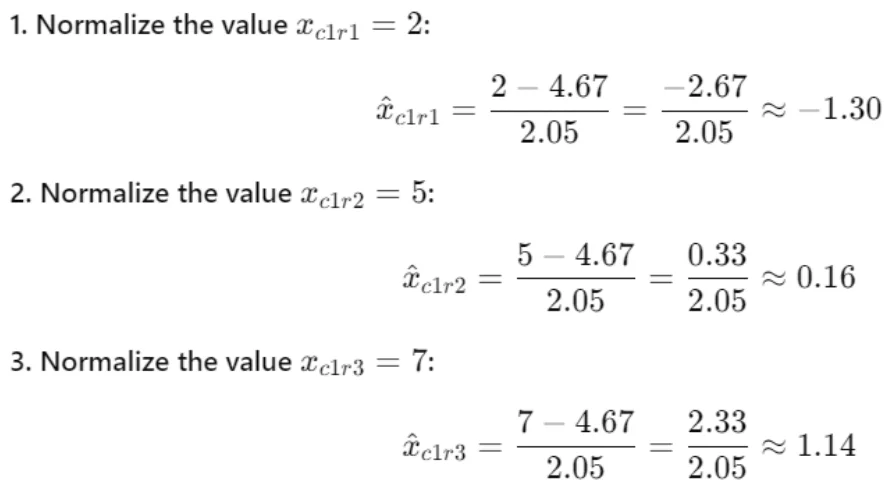
Finally, we got the batch normalized values for the first column (2,5,7) which are -1.30,0.16 and 1.14.
Now, lets look into layer normalization
On the other hand if we look at layer normalization the mean and standard deviation is calculated on the basis of the values in a row.
Point 2 : Batch Normalization works better with larger batch size and is mostly used in Convolutional Neural Network (CNN). If we see layer normalization it works well with lower batch size and is mostly used in RNN and Transformers.
Batch normalization is applied at the intermediate level of the neural network but the layer normalization is applied across the neural network.
Layer Normalization, on the other hand, is a technique used to normalize the activations of a layer across the entire layer, independently for each sample in the batch. It is commonly applied to intermediate layers of a neural network to help stabilize training, reduce internal covariate shift, and improve the convergence of the model.
Frequently asked questions.
Is layer normalization the same as batch normalization?
When to use batch normalization ?
We should use batch normalization when we have a large batch size. Generally we use batch normalization convolutional neural networks or feedforward networks.
When to use Layer normalization ?
Code difference: Layer normalization vs Batch normalization
Layer normalization code
import numpy as np import tensorflow as tf from tensorflow.keras import layers, models from tensorflow.keras.datasets import imdb from tensorflow.keras.preprocessing.sequence import pad_sequencesLoading and preprocessing the IMDB dataset
max_features = 10000 # Number of words to consider as features maxlen = 200 # Cut texts after this number of words (among top max_features most common words) (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)Pad sequences to ensure uniform input size
x_train = pad_sequences(x_train, maxlen=maxlen) x_test = pad_sequences(x_test, maxlen=maxlen)Implementing Layer Normalization in RNN model
model_ln = models.Sequential()
model_ln.add(layers.Embedding(max_features, 128, input_length=maxlen))
model_ln.add(layers.SimpleRNN(32, return_sequences=True))
model_ln.add(layers.LayerNormalization()) # Layer Normalization
model_ln.add(layers.SimpleRNN(32))
model_ln.add(layers.LayerNormalization()) # Layer Normalization
model_ln.add(layers.Dense(1, activation='sigmoid'))
model_ln.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print("\nTraining Layer Normalization model:")
model_ln.fit(x_train, y_train, epochs=5, batch_size=64, validation_split=0.2)
Evaluating the model
print("\nEvaluating Layer Normalization model:")
test_loss_ln, test_acc_ln = model_ln.evaluate(x_test, y_test)
print(f"Test accuracy (Layer Normalization): {test_acc_ln}")
Output
Training Layer Normalization model: Epoch 1/5 313/313 ━━━━━━━━━━━━━━━━━━━━ 46s 134ms/step - accuracy: 0.5709 - loss: 0.6883 - val_accuracy: 0.8062 - val_loss: 0.4356 Epoch 2/5 313/313 ━━━━━━━━━━━━━━━━━━━━ 82s 135ms/step - accuracy: 0.8592 - loss: 0.3340 - val_accuracy: 0.7752 - val_loss: 0.4884 Epoch 3/5 313/313 ━━━━━━━━━━━━━━━━━━━━ 81s 133ms/step - accuracy: 0.9431 - loss: 0.1633 - val_accuracy: 0.8250 - val_loss: 0.4929 Epoch 4/5 313/313 ━━━━━━━━━━━━━━━━━━━━ 41s 133ms/step - accuracy: 0.9727 - loss: 0.0814 - val_accuracy: 0.7854 - val_loss: 0.5845 Epoch 5/5 313/313 ━━━━━━━━━━━━━━━━━━━━ 85s 144ms/step - accuracy: 0.9792 - loss: 0.0658 - val_accuracy: 0.7620 - val_loss: 0.7839 Evaluating Layer Normalization model: 782/782 ━━━━━━━━━━━━━━━━━━━━ 20s 26ms/step - accuracy: 0.7655 - loss: 0.7557 Test accuracy (Layer Normalization): 0.7704399824142456
Batch normalization
import numpy as np import tensorflow as tf from tensorflow.keras import layers, models from tensorflow.keras.datasets import cifar10 from tensorflow.keras.utils import to_categoricalLoad and preprocess the CIFAR-10 dataset
(x_train, y_train), (x_test, y_test) = cifar10.load_data()Normalizing pixel values between 0 and 1
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
Implementing one hot encode for target labels
y_train = to_categorical(y_train, num_classes=10) y_test = to_categorical(y_test, num_classes=10)Building a CNN model with Batch Normalization.
model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3))) model.add(layers.BatchNormalization()) # Batch Normalization after the first Conv layer model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.BatchNormalization()) # Batch Normalization after the second Conv layer model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.BatchNormalization()) # Batch Normalization after the third Conv layer model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dense(128, activation='relu')) model.add(layers.BatchNormalization()) # Batch Normalization before output layer model.add(layers.Dense(10, activation='softmax'))Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])Train the model
print("Training the CNN model with Batch Normalization:")
model.fit(x_train, y_train, epochs=10, batch_size=64, validation_split=0.2)
Evaluating the model
print("\nEvaluating the model:")
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Test accuracy: {test_acc}")
Output
Training the CNN model with Batch Normalization: Epoch 1/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 81s 124ms/step - accuracy: 0.4503 - loss: 1.5704 - val_accuracy: 0.5625 - val_loss: 1.2145 Epoch 2/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 82s 124ms/step - accuracy: 0.6521 - loss: 0.9924 - val_accuracy: 0.6083 - val_loss: 1.1572 Epoch 3/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 82s 124ms/step - accuracy: 0.7233 - loss: 0.7931 - val_accuracy: 0.6469 - val_loss: 1.0261 Epoch 4/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 77s 123ms/step - accuracy: 0.7629 - loss: 0.6676 - val_accuracy: 0.5587 - val_loss: 1.4448 Epoch 5/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 82s 122ms/step - accuracy: 0.8042 - loss: 0.5684 - val_accuracy: 0.6580 - val_loss: 1.0414 Epoch 6/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 75s 120ms/step - accuracy: 0.8289 - loss: 0.4931 - val_accuracy: 0.6284 - val_loss: 1.1746 Epoch 7/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 81s 119ms/step - accuracy: 0.8593 - loss: 0.4066 - val_accuracy: 0.6885 - val_loss: 0.9976 Epoch 8/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 84s 122ms/step - accuracy: 0.8824 - loss: 0.3424 - val_accuracy: 0.6720 - val_loss: 1.1566 Epoch 9/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 81s 120ms/step - accuracy: 0.9000 - loss: 0.2938 - val_accuracy: 0.6863 - val_loss: 1.0915 Epoch 10/10 625/625 ━━━━━━━━━━━━━━━━━━━━ 76s 121ms/step - accuracy: 0.9145 - loss: 0.2475 - val_accuracy: 0.6909 - val_loss: 1.0913 Evaluating the model: 313/313 ━━━━━━━━━━━━━━━━━━━━ 5s 15ms/step - accuracy: 0.6947 - loss: 1.0877 Test accuracy: 0.6886000037193298
Conclusion
In the blog we saw the difference between layer normalization vs batch normalization and also understood when to use layer normalization and batch normalization. You can also read the difference between l1 and l2 regularization in machine learning.